Introduction to XML
Updated on 28 Dec 2022
Introduction
XML is a way to represent data. In these examples we’ll use the well defined DOM library which is also implemented in other languages.
You can see the equivalent representation of this in the json introduction section.
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
Basic access
We will use DOM library for reading XML files. This is a common library found across several programming languages. As a basic example we’ll try this:
from xml.dom import minidom
doc = minidom.parse("xml_data1.xml")
# doc.getElementsByTagName returns NodeList
country = doc.getElementsByTagName("country")[0]
print(country.nodeName)
print(country.nodeType)
print(country.parentNode)
print(country.attributes)
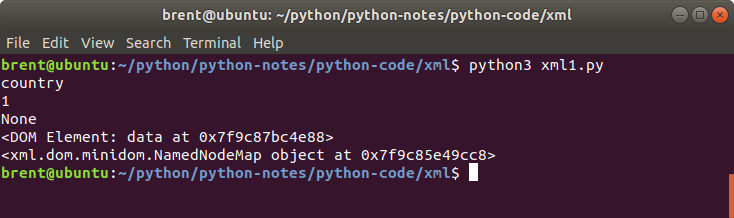
- nodeName the name of the tag. In this example,
country. - nodeType returns the an integer value that represents ELEMENT_NODE, ATTRIBUTE_NODE, TEXT_NODE, CDATA_SECTION_NODE, ENTITY_NODE, PROCESSING_INSTRUCTION_NODE, COMMENT_NODE, DOCUMENT_NODE, DOCUMENT_TYPE_NODE, NOTATION_NODE
- parentNode returns the parent node. I.e. for
countrythe parent node isdata. - attributes returns the …
Looping, elements and attributes
We can loop thru the child nodes of an XML document with a standard for loop.
from xml.dom import minidom
doc = minidom.parse("xml_data1.xml")
# doc.getElementsByTagName returns NodeList
countries = doc.getElementsByTagName("country")
gdppc = doc.getElementsByTagName("gdppc")
print("There are {0} countries in the xml document".format(countries.length))
print("There are {0} records for GDPCC".format(gdppc.length))
for country in countries:
nameValue = country.getAttribute("name")
rankNode = country.getElementsByTagName('rank')[0]
rankValue = rankNode.firstChild.data
print("{0}: {1}".format(nameValue, rankValue))
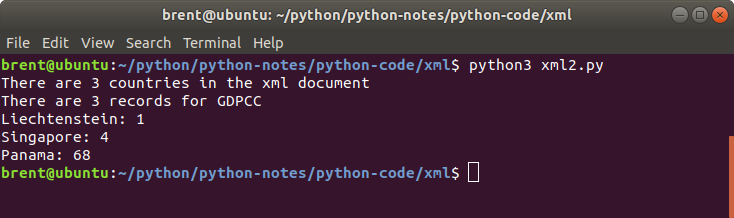
Some pointers
doc.getElementsByTagName("...") returns a nodeList. We can use this to loop thru with a normal for loop.
Notice that even if we get the rank node, we still need to get the firstChild in order to get the value enclosed by the tags. This structure might help:
<rank>blah blah</rank>
- rank -> element node
- blah blah -> text node
The data property will actually get us the actual value, but this is only available for text nodes.
Loading an xml file
Loading an xml object can be done with the following methods:
- parseString -> from a string
- parse -> from a file
Unlike Json, parse is a little easier to use because you are supplying a filename to load.
from xml.dom import minidom
doc = minidom.parse("xml_data1.xml")
Saving an xml file
Saving an xml object can be done with node.writexml, and unlike parse that accepts a filename, writexml requires that you pass it an object that has write capabilities. It is a bit of a pain.
from xml.dom import minidom
xml = '<?xml version="1.0"?><data><country name="Liechtenstein"><rank>1</rank></country></data>'
doc = minidom.parseString(xml)
file_handle = open("xml_file.xml","w")
doc.writexml(file_handle)
file_handle.close()
XML - guided exercise
In our example for Classes we ended up with a Quote.py that had a list of quotes. There are 2 things that I want to do:
- expand the Quote class to include a rating and group section
- read and save the quotes, rating and group to a file
- do all of this using XML
Solution
First step is to have a look at how we are storing the Quotes in the class, and modify that to how we want to store the quotes.
# this is a constructor
def __init__(self):
self.quotes = [
'git',
'imbecile',
'invented TIM',
'need to ask yourself, what are we really trying to solve'
] # instance variable
I think we can change this to something like what is below. This is not xml, but it is how we represent data in Python. When it comes to saving the data, we can do that in xml structure.
# this is a constructor
def __init__(self):
self.quotes = [
{
"quote": "git",
"rating": 1,
"group": "tech"
},
{
"quote": "imbecile",
"rating": 3,
"group": "insults"
},
{
"quote": "invented TIM",
"rating": 3,
"group": "tech"
},
{
"quote": "need to ask yourself, what are we really trying to solve",
"rating": 7,
"group": "insults"
}
] # instance variable
add_quote - good example
The current append method for the quotes list works as is, and will work perfectly well for us if we adhere to the rules. I.e. we add_quote that matches the current signature; quote, rating, group.
import Quote4
# 1st Quote is the filename
# 2nd Quote is the classname
# random_quote is the method in the Quote class
myQuotes = Quote4.Quote()
myQuotes.add_quote({'quote': 'added this myself!', 'rating': 20, 'group': 'insults'})
print(myQuotes.get_all_quotes())
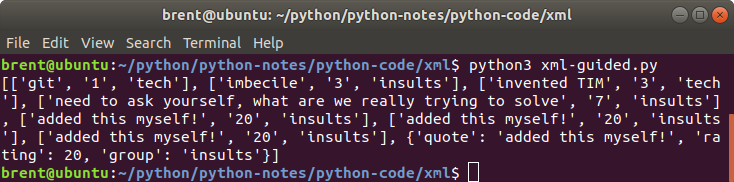
add_quote - bad example
If however we simply use the existing code from the classes section then things don’t quite work out for us.
import Quote4
# 1st Quote is the filename
# 2nd Quote is the classname
# random_quote is the method in the Quote class
myQuotes = Quote4.Quote()
myQuotes.add_quote('added this myself!')
print(myQuotes.get_all_quotes())
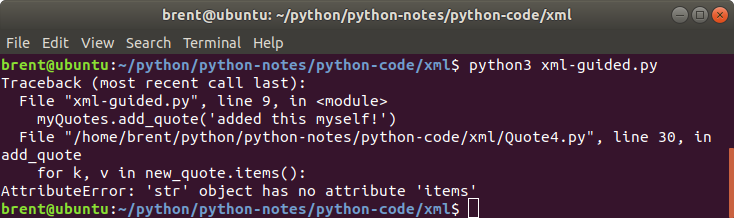
We can see here that when we added our quote, it is essentially unstructured. That means using code like this: print(myQuotes.random_quote()['group']) will definitely fail if it picks out the last quote because there is no group (or quote or rating).
Converting existing quotes to XML
Next step is to convert the existing quote data to an xml file, and load that in our Quote class. For this I’m going to opt for a fairly basic xml structure and save the file as xml_quotes.xml.
<?xml version="1.0"?>
<quotes>
<item>
<quote>git</quote>
<rating>1</rating>
<group>tech</group>
</item>
<item>
<quote>imbecile</quote>
<rating>3</rating>
<group>insults</group>
</item>
<item>
<quote>invented TIM</quote>
<rating>3</rating>
<group>tech</group>
</item>
<item>
<quote>need to ask yourself, what are we really trying to solve</quote>
<rating>7</rating>
<group>insults</group>
</item>
</quotes>
Updating the Quotes.py file
So I don’t get muddled up with my earlier stuff, I’ll create a new file called Quotes4.py to hold all our new modifications to the class. Remember
- Quotes2.py -> guided exercise (json)
- Quotes3.py -> extended exercise (json)
Quotes4.py
import random
from xml.dom import minidom
class Quote:
staticVar = 'this is a class variable'
# this is a constructor
def __init__(self):
doc = minidom.parse("xml_quotes.xml")
items = doc.getElementsByTagName("item")
self.quotes = []
for item in items:
quote = item.getElementsByTagName('quote')[0].firstChild.data
rating = item.getElementsByTagName('rating')[0].firstChild.data
group = item.getElementsByTagName('group')[0].firstChild.data
myQuote = [quote, rating, group]
self.quotes.append(myQuote)
.
.
.
As we can see in this code snippet, working with XML is not that easy. There is a lot of code we have to type just to get the data that we want.
Testing the new Quotes class
xml-guided.py
import Quote4
# 1st Quote2 is the filename
# 2nd Quote is the classname
# random_quote is the method in the Quote class
myQuotes = Quote4.Quote()
# myQuotes.add_quote('added this myself!')
myQuotes.add_quote({'quote': 'added this myself!', 'rating': 20, 'group': 'insults'})
print(myQuotes.get_all_quotes())
Saving added quotes
If you thought retrieving data from an XML file was a nuisance, just wait until you see the process involved for manipulating an XML file.
def add_quote(self, new_quote):
self.quotes.append(new_quote)
newItemNode = self.doc.createElement('item')
for k, v in new_quote.items():
newNode = self.doc.createElement(k)
newText = self.doc.createTextNode(str(v))
newNode.appendChild(newText)
newItemNode.appendChild(newNode)
quotes = self.doc.getElementsByTagName('quotes')[0]
quotes.appendChild(newItemNode)
file_handle = open("xml_quotes.xml","w")
self.doc.writexml(file_handle)
file_handle.close()
Some of the DOM functions that we are using in this example include:
- createElement -> creates a new element
- createTextNode -> creates the text value
- appendChild -> attachs the text value to the new element, and the new element to the document
- writexml -> saves the XML to file
Now compare that to what we did with Json. You’ll appreciate that where we have a choice, json is a better structure because it is a natural fit to Python and requires significantly less coding and less complexity.
json version
def add_quote(self, new_quote):
self.quotes.append(new_quote)
with open('json_quotes.json', 'w') as f:
json.dump(self.quotes, f, indent=4)
Full version of Quote4.py
import random
from xml.dom import minidom
class Quote:
staticVar = 'this is a class variable'
# this is a constructor
def __init__(self):
self.doc = minidom.parse("xml_quotes.xml")
items = self.doc.getElementsByTagName("item")
self.quotes = []
for item in items:
quote = item.getElementsByTagName('quote')[0].firstChild.data
rating = item.getElementsByTagName('rating')[0].firstChild.data
group = item.getElementsByTagName('group')[0].firstChild.data
myQuote = [quote, rating, group]
self.quotes.append(myQuote)
def random_quote(self):
return random.choice(self.quotes)
def add_quote(self, new_quote):
self.quotes.append(new_quote)
newItemNode = self.doc.createElement('item')
for k, v in new_quote.items():
newNode = self.doc.createElement(k)
newText = self.doc.createTextNode(str(v))
newNode.appendChild(newText)
newItemNode.appendChild(newNode)
quotes = self.doc.getElementsByTagName('quotes')[0]
quotes.appendChild(newItemNode)
file_handle = open("xml_quotes.xml","w")
self.doc.writexml(file_handle)
file_handle.close()
def get_all_quotes(self):
return self.quotes
if __name__ == "__main__":
print('this should be imported into a main application...')
Extended exercise 1
If we run xml-guided.py a few times we’ll notice that the xml added to xml_quotes.xml is not nicely formatted like the rest of the file. Have a look at the documentation and see if you can find a function that will make our new xml that we are adding format nicely like the rest of the document.
Extended exercise 2
If we run xml-guided.py a few more times we’ll notice that the add_quote function will continually add the same quote to the file. Use your knowledge that you’ve gained so far to see if you can prevent the same quote from being added to xml_quotes.xml.
Extended exercise 3
We might change the data structure for our random_quotes, and it might look something like this now.
<quotes>
<group type="tech">
<item>
<quote>git</quote>
<rating>1</rating>
</item>
<item>
<quote>invented TIM</quote>
<rating>3</rating>
</item>
</group>
<group type="insults">
<item>
<quote>imbecile</quote>
<rating>3</rating>
</item>
<item>
<quote>need to ask yourself, what are we really trying to solve</quote>
<rating>7</rating>
</item>
</group>
</quotes>
Create a new Quote5.py file (from Quote4.py) that can work with this new structure.
Hint, you might try writing some sample code that can access the quotes first before trying to modify the class. Also you will need to work with xml attributes to get the group type.