Reading Excel files
Updated on 28 Dec 2022
In this chapter we continue to explore pyexcel a Python module that is installed with pip.
Note: pyexcel can render the value from a formula, openpyxl can determine if cells are highlighted.
Installing pyexcel
On the windows machine we can install additional Python modules with the following command.
pip install pyexcel --user
pip install pyexcel-xlsx --user
This will allow the modules to be installed in a local directory - bypassing the issue of installing applications in program files.
Reading an XLSX file - list of lists
Reading an Excel spreadsheet with Pyexcel is a fairly straight-forward process. Consider the following excel spreadsheet.
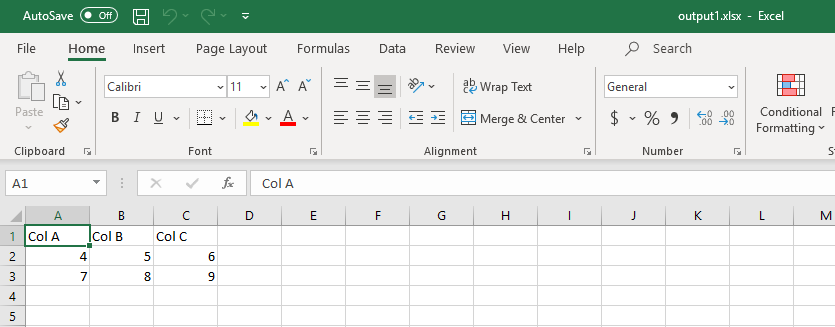
Basic reading of a spreadsheet can be done with get_array function.
import pyexcel
xlsx_file = 'data/output1.xlsx'
data = pyexcel.get_array(file_name=xlsx_file, name_columns_by_row=0)
for row in data:
print('{0} - {1}'.format(row, row[1]))
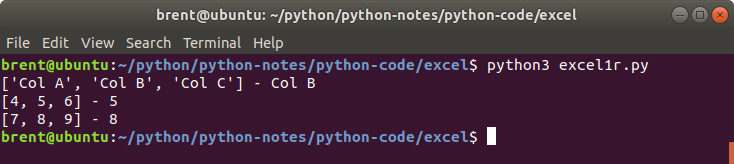
What is happening here is that we are retrieving the entire contents of the sheet into a 2-dimensional list. Earlier when we wrote data to a spreadsheet in this format.
#-- create a data array.
data = [
['Col A', 'Col B', 'Col C'],
[4, 5, 6],
[7, 8, 9]
]
We will also retrieve data in a similar format. So in the above code
for row in data:
print('{0} - {1}'.format(row, row[1]))
For the first row we would expect to see ['Col A', 'Col B', 'Col C'] and for row[1] we will see Col B.
Reading an XLSX file - list of dictionaries
Another option is to read the contents into a list of dictionaries. We do that with get_records function.
import pyexcel
xlsx_file = 'data/output1.xlsx'
data = pyexcel.get_records(file_name=xlsx_file, name_columns_by_row=0)
for row in data:
print('{0} - {1}'.format(row, row['Col B']))
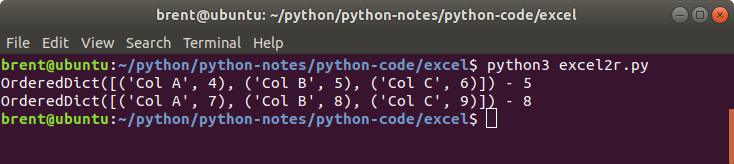
Compared to the earlier example we now refer to the columns by their name.
- get_array use index value (uses list)
- get_records use header column value (uses dict, 1st row = keys)
Main methods of reading
There are 4 main methods for reading data using pyexcel.
get_array()a list of listsget_records()a list of dictionariesget_dict()a dictionary of one dimensional arrays an ordered dictionary of listsget_book_dict()a dictionary of two dimensional arrays a dictionary of lists of lists
The 2 previous topics covered the first 2 methods.
Reading a particular cell - openpyxl
pyexcel is good for reading sheets, however openpyxl is great for getting at individual cells and looking at formula’s and cell formatting / styling. Unfortunately I wish I could find the relevant documentation for what I have done below, but I just can’t seem to find it!
Consider the following spreadsheet.
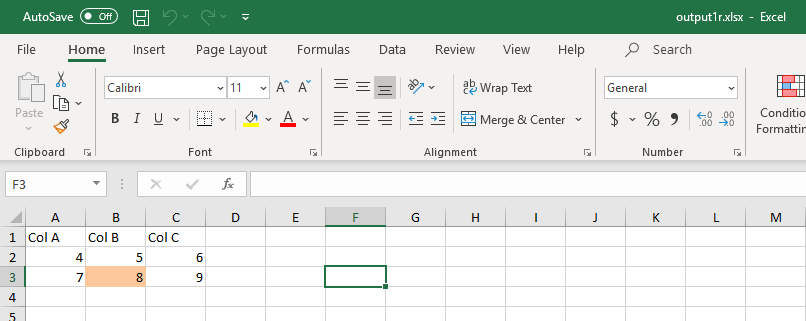
Imagine that we wanted to see if cell B3 was highlighted in the light orange color.
import openpyxl
xlsx_file = 'data/output1r.xlsx'
wb = openpyxl.load_workbook(filename = xlsx_file)
sheet = wb.active
if sheet['B3'].fill.bgColor.rgb == 'FFC0C0C0':
print('Hey, we have the correct background color ' )
print(sheet['B3'].value)
Here we are using the openpyxl to read the spreadsheet and gain access to an individual cell.

Guided Exercise - extracting certain rows
Lets use data/output1r.xlsx and extract only those records where the value of Column B is equal to 8. We should have an output similar to what is shown below.

Solution
Let’s start off with some basic code that we’re already familiar with, and build on from there.
import pyexcel
xlsx_file = 'data/output1r.xlsx'
data = pyexcel.get_array(file_name=xlsx_file, name_columns_by_row=0)
for row in data:
print('{0} - {1}'.format(row, row[1]))
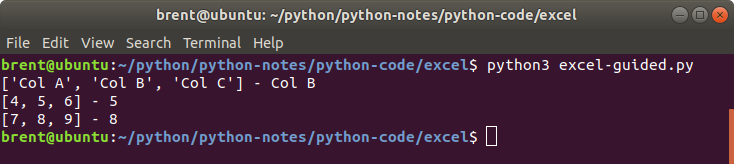
Based on what we can see in the output we can use row and row[1] with our next step. I’m thinking, check the value of row[1] (which is column B) and then append row to another list that we’ve created.
import pyexcel
xlsx_file = 'data/output1r.xlsx'
data = pyexcel.get_array(file_name=xlsx_file, name_columns_by_row=0)
okay_rows = [['Col A', 'Col B', 'Col C']]
for row in data:
if row[1] == 8:
okay_rows.append(row)
print(okay_rows)
Notice that okay_rows is defined as a list inside a list with 'Col A', 'Col B' etc. It might be easier to understand okay_rows like below where I have defined separate row variables (list) and added them to okay_rows :
row1 = ['Col A', 'Col B', 'Col C']
row2 = ['4', '5', '6']
row3 = ['7', '8', '9']
okay_rows = [
row1,
row3
]
Guided Exercise - extended
Lets use data/output1r.xlsx and extract only those records where the cell in Column B is highlighted.